 ICT4LT Module 3.5ICT4LT Module 3.5
ICT4LT Module 3.5ICT4LT Module 3.5It is the aim of this module to explore some of the aspects and challenges in Human Language Technologies (HLT) that are of relevance to Computer Assisted Language Learning (CALL). Starting with a brief outline of some of the early attempts in HLT, using the example of Machine Translation (MT), it will become apparent that experiences and results in this area had a direct bearing on some of the developments in CALL. CALL soon became a multi-disciplinary field of research, development and practice. Some researchers began to develop CALL applications that made use of Human Language Technologies, and a few such applications will be introduced in this module. The advantages and limitations of applying HLT to CALL will be discussed, using the example of parser-based CALL. This brief discussion will form the basis for first hypotheses about the nature of human-computer interaction (HCI) in parser-based CALL.
This Web page is designed to be read from the printed page. Use File / Print in your browser to produce a printed copy. After you have digested the contents of the printed copy, come back to the onscreen version to follow up the hyperlinks.
Piklu Gupta: At this time of writing this module Piklu was a lecturer in German Linguistics at the University of Hull, UK. He is now working for Fraunhofer IPSI.
Mathias Schulze: At this time of writing this module Mathias was a lecturer in German at UMIST, now merged with the University of Manchester, UK. He is now working at the University of Waterloo, Canada. His main research interest is in parser-based CALL and linguistics. He is an active member of the NLP SIG within the EUROCALL professional association and ICALL within the CALICO professional association.
Graham Davies, ICT4LT Editor, Thames Valley University, UK. Graham has been interested in Machine Translation since 1976.
A translation of this module into Belorussian by Alyona Lompar can be found at http://www.webhostinghub.com/support/by/edu/hlt-call-be
Human Language Technologies (HLT) is a relatively new term that embraces a wide range of areas of research and development in the sphere of what used to be called Language Technologies or Language Engineering. The aim of this module is to familiarise the student with key areas of HLT, including a range of Natural Language Processing (NLP) applications. NLP is a general term used to describe the use of computers to process information expressed in natural (i.e. human) languages. The term NLP is used in a number of different contexts in this document and is one of the most important branches of HLT. There is a Special Interest Group in Language Processing, NLP SIG, within the EUROCALL professional association, and a Special Interest Group in Intelligent Computer Assisted Language Instruction (ICALL) within the CALICO professional association. Both have similar aims, namely to further research in a number of areas that are mentioned in this module, such as:
All of the above are areas of research that have produced results which have proven, are proving and will prove very useful in the field of Computer Assisted Language Learning.
Of course, this module cannot teach you everything there is to know about HLT. This is neither necessary nor possible. The two main authors of this module are living proof of that; they both started off as language teachers and then got interested in HLT.
A useful introductory publication, Language and technology: from the Tower of Babel to the Global Village, was published by the European Commission in 1996.
A multilingual CD-ROM titled A world of understanding was produced in 1998 on behalf of the Information Society and Media Directorate General of the European Commission under its former name, DGXIII. The aim of the CD-ROM was to demonstrate the importance of HLT in helping to realise the benefits of the Multilingual Information Society, in particular forming a review and record of the Language Engineering Sector of the Fourth Framework Programme of the European Union (1994-98).
[...] there is no doubt that the development of tools (technology) depends on language - it is difficult to imagine how any tool - from a chisel to a CAT scanner - could be built without communication, without language. What is less obvious is that the development and the evolution of language - its effectiveness in communicating faster, with more people, and with greater clarity - depends more and more on sophisticated tools. (European Commission: Language and technology 1996:1)
Language and technology lists the following examples of language technology (using an admittedly broad understanding of the term):
Many of these are already being used in language learning and teaching. Today most of the research and development that aims to enable humans to communicate more effectively with each other (e.g. email and Web-conferencing) and with machines (e.g. machine translation and natural language interfaces for search engines) is carried out in the context of Human Language Technologies:
The field of human language technology covers a broad range of activities with the eventual goal of enabling people to communicate with machines using natural communication skills. Research and development activities include the coding, recognition, interpretation, translation, and generation of language. [...] Advances in human language technology offer the promise of nearly universal access to online information and services. Since almost everyone speaks and understands a language, the development of spoken language systems will allow the average person to interact with computers without special skills or training, using common devices such as the telephone. These systems will combine spoken language understanding and generation to allow people to interact with computers using speech to obtain information on virtually any topic, to conduct business and to communicate with each other more effectively. [Source: Foreword to (Cole 1997)]
Facilitating and supporting all aspects of human communication through machines has interested researchers for a number of centuries. The use of mechanical devices to overcome language barriers was proposed first in the seventeenth century. Then, suggestions for numerical codes to be used to mediate between languages were made by Leibnitz, Descartes and others (v. Hutchins 1986:21). The beginnings of what we describe today as Human Language Technologies are, of course, closely connected to the advent of computers. In a report titled Intelligent Machinery, which was written in 1948 for the National Physical Laboratory, Alan Turing, one of the fathers of Artificial Intelligence (AI), who led work on cryptanalysis in World War II using the Colossus machine at Bletchley Park, mentions a number of different ways in which these new computers could demonstrate their "intelligence", including learning and translating natural languages:
(i) Various games, e.g. chess, noughts and crosses, bridge, poker
(ii) The learning of languages
(iii) Translation of languages
(iv) Cryptography
(v) Mathematics
Of these (i), (iv), and to a lesser extent (iii) and (v) are good in that they require little contact with the outside world. For instance in order that the machine should be able to play games its only organs need be 'eyes' capable of distinguishing the various positions on a specially made board, and means for announcing its own moves. Mathematics should preferably be resticted to branches where diagrams are not much used. Of the above possible fields the learning of languages would be the most impressive, since it is the most human of these activities. This field sees however to depend too much on sense organs and locomotion to be feasible. (Turing 1948:9)
Later on, Machine Translation enjoyed a period of popularity with researchers and funding bodies in the United States and the Soviet Union:
From 1956 onwards, the dollars (and roubles) really started to flow. Between 1956 and 1959, no less than twelve research groups became established at various US universities and private corporations and research centres. [...] The kind of optimism and enthusiasm with which researchers tackled the task of MT [Machine Translation] may be illustrated best by some prophecies of Reifler, whose views may be taken as representative of those of most MT workers at that time: " [...] it will not be very long before the remaining linguistic problems in machine translation will be solved for a number of important languages" (Reifler 1958:518), and, "in about two years (from August 1957), we shall have a device which will at a glance read a whole page and feed what it has read into a tape recorder and thus remove all human co-operation on the input side of the translation machines" (Reifler 1958:516 ), (Buchmann 1987:14)
Although linguists, language teachers and computer users today may find these predictions ridiculous, it was the enthusiasm and the work during this time that form the basis of many developments in HLT today.
Research and development in HLT is nowadays more rapidly transferred into commercial systems than was the case up until the 1980s. Indeed HLT is becoming increasingly pervasive in our everyday lives. Here are some examples:
Other previously unexpected areas of use are emerging. It is now, for instance, common for mobile phones to have what is known as predictive text input to aid the writing of short text messages. Instead of having to press one of the nine keys a number of times to produce the correct letter in a word, software in the phone compares users' key presses to a linguistic database to determine the correct (or most likely) word. Most Internet search engines also now incorporate some kind of linguistic technology to enable users to enter a query in natural language, for example "What is meant by log-likelihood ratio?" is as acceptable a query as simply "log-likelihood ratio".
What are the possible benefits for language teaching and learning of using HLT? Here are some examples:
Machine Translation (MT) has been the dream of computer scientists since the 1940s. The student's attention is drawn in particular to the following publications, which provide a very useful introduction to MT:
Initial work on Machine Translation (MT) systems was typified by what we would now consider to be a naive approach to the "problem" of natural language translation. Successful decoding of encrypted messages by machines during World War II led some scientists, most notably Warren Weaver, to view the translation process as essentially analogous with decoding. The concept of Machine Translation in the modern age can be traced back to the 1940s. Warren Weaver, Director of the Natural Sciences Division of the Rockefeller Foundation, wrote to his friend Norbert Wiener on 4 March 1947 - shortly after the first computers and computer programs had been produced:
Recognising fully, even though necessarily vaguely, the semantic difficulties because of multiple meanings, etc., I have wondered if it were unthinkable to design a computer which would translate. Even if it would translate only scientific material (where the semantic difficulties are very notably less), and even if it did produce an inelegant (but intelligible) result, it would seem to me worth while.
Also knowing nothing official about, but having guessed and inferred considerable about, powerful new mechanized methods in cryptography - methods which I believe succeed even when one does not know what language has been coded - one naturally wonders if the problem of translation could conceivably be treated as a problem in cryptography. When I look at an article in Russian, I say "This is really written in English, but it has been coded in some strange symbols. I will now proceed to decode".
Have you ever thought about this? As a linguist and expert on computers, do you think it is worth thinking about? Cited in Hutchins (1997).
Weaver was possibly chastened by Wiener's pessimistic reply:
I frankly am afraid the boundaries of words in different languages are too vague and the emotional and international connotations are too extensive to make any quasi-mechanical translation scheme very hopeful.
But Weaver remained undeterred and composed his famous 1949 Memorandum, titled simply "Translation", which he sent to some 30 noteworthy minds of the time. It posited in more detail the need for and possibility of MT. Thus began the first era of MT research.
The first generation (henceforth referred to as 1G) of MT systems worked on the principle of direct transfer; that is to say that the route taken from source language text to its target language equivalent was a short one consisting essentially of two processes: replacement and adjustment. A direct system would comprise a bilingual dictionary containing potential replacements or target language equivalents for each word in the source language. A restriction of such MT systems was therefore that they were unidirectional and could not accommodate many languages unlike the systems that followed. Rules for choosing correct replacements were incorporated but functioned on a basic level; although there was some initial morphological analysis prior to dictionary lookup, subsequent local re-ordering and final generation of the target text, there was no scope for syntactic analysis let alone semantic analysis! Inevitably this often led to poor quality output, which certainly contributed to the severe criticism of MT in the 1966 Automatic Language Processing Advisory Committee (ALPAC) report which stated that it saw little use for MT in the foreseeable future. The damning judgment of the ALPAC report effectively halted research funding for machine translation in the USA throughout the 1960s and 1970s.
We can say that both technical constraints and the lack of a linguistic basis hampered MT systems. The system developed at Georgetown University, Washington DC, and first demonstrated at IBM in New York in 1954 had no clear separation of translation knowledge and processing algorithms, making modification of the system difficult.
In the period following the ALPAC report the need was increasingly felt for an approach to MT system design which would avoid many of the pitfalls of 1G systems. By this time opinion had shifted towards the view that linguistic developments should influence system design and development. Indeed it can be said that the second generation (2G) of "indirect" systems owed much to linguistic theories of the time. Modularity is an important design feature of 2G systems, and in contrast to 1G systems, which operate on a 'brute force' principle in which translation takes place in one step, the steps involved in analysis of source text and generation of target text ideally constitute distinct processes. 2G systems can be divided essentially into "interlingual" and "transfer" systems. We will look first of all at interlingual systems, or rather those claiming to adopt an interlingual approach.
Although Warren Weaver had put forward the idea of an intermediary "universal" language as a possible route to machine translation in his 1947 letter to Norbert Wiener, linguistics was unable to offer any models to apply until the 1960s. By virtue of its introduction of the concept of "deep structure", Noam Chomsky's theory of transformational generative grammar appeared to offer a route towards "universal" semantic representations and thus appeared to provide a model for the structure of a so-called interlingua. An interlingua is not a natural language, rather it can be seen as a meaning representation which is independent of both the source and the target language of translation. An interlingua system maps from a language's surface structure to the interlingua and vice versa. A truly interlingual approach to system design has obvious advantages, the most important of which is economy, since an interlingual representation can be applied for any language pair and facilitates addition of other language pairs without major additions to the system. The next section looks at "transfer" systems.
In a transfer model the intermediate representation is language dependent, there being a bilingual module whose function it is to interpose between source language and target language intermediate representations. Thus we cannot say that the transfer module is language independent. The nature of these transfer modules has obvious ramifications for system design in that addition of another language to a system necessitates not only modules for analysis and synthesis but also additional transfer modules, whose number is dictated by the number of languages in the existing system and which would increase polynomially according to the number of additional languages required. (For n languages the number of transfer modules required would be n(n-1) or n(n-1) /2 if the modules are reversible).
An important advance in 2G systems when compared to 1G was the separation of algorithms (software) from linguistic data (lingware). In a system such as the Georgetown model the program mixed language modelling, translation and the processing thereof in one program. This meant that the program was monolithic and it was easy to introduce errors when trying to rectify an existing shortcoming. The move towards separating software and lingware was hastened by parallel advances in both computational and linguistic techniques. The adoption of linguistic formalisms in the design of systems and the development of high level programming languages enabled MT workers to code in a more problem-oriented way. The development in programming languages meant that it was becoming ever easier to code rules for translation in a meaningful manner and arguably improved the quality of these rules. The declarative nature of linguistic description could now be far more explicitly reflected in the design of programs for MT.
Early MT systems were predominantly parser-based, one of the first steps in such a system being to parse and tag the source language: see Section 5 on Parsing and Tagging. More recent current approaches to MT rely less on formal linguistic descriptions than the transfer approach described above. Translation Memory (TM) systems are now in widespread commercial use: see below and Chapter 10 of Arnold et al. (1994).
Example-Based Machine Translation (EBMT) is a relatively new technology which aims to combine both traditional MT and more recent TM paradigms by reusing previous translations and applying various degrees of linguistic knowledge to convert fuzzy matches into exact ones: see the Wikipedia article on EBMT. However, some early definitions of EBMT refer to what is now known as TM and they often exclude the concept of fuzzy matches.
An even more radical approach to MT is the Statistical Machine Translation (SMT) approach, which requires the use of large bilingual corpora which serve as input for a statistical translation model: see Brown et al. (1993) and the Wikipedia article on Statistical Machine Translation. Google Translate uses the SMT approach . Read How Google translate works, an article by David Bellos in The Independent, 13 September 2011, an extract from his book on translation (Bellos 2011). See also the YouTube video, Inside Google Translate, and the ICT4LT blog (November 2011), Google Translate: friend or foe?
Essentially, Google Translate begins by examining and comparing massive corpora of texts on the Web that have already been translated by human beings. It looks for matches between source and target texts and uses complex statistical analysis routines to look for statistically significant patterns, i.e. it works out the rules of the interrelationships between source and target texts for itself. As more and more corpora are added to the Web this means that Google Translate will keep improving until it reaches a point where it will be very difficult to tell that a machine has done the translation. I remember early machine translation tools translating "Wie geht es dir?" as "How goes it you?" Now Google Translate gets it right: "How are you?"
Google Translate also includes a Text To Speech (TTS) facility: see Section 4.1, Speech synthesis
Thus we have, in a sense, come full circle in that Weaver's ideas of applying statistical techniques are seen as a fruitful basis for MT.
There are many automatic translation packages on the market - as well as free packages on the Web. While such packages may be useful for extracting the gist of a text they should not be seen as a serious replacement for the human translator. Some are not all that bad, producing translations that are half-intelligible, letting you know whether a text is worth having translated properly. See:
Professional human translators are making increasing use of Translation Memory (TM) packages. TM packages store texts that have previously been translated, together with their source texts, in a large database. Chunks of new texts to be translated are then matched against the translated texts in the database and suggested translations are offered to the human translator wherever a match is found. The human translator has to intervene regularly in this process of translation, making corrections and amendments as necessary. TM systems can save hours of time (estimated at up to 80% of a translator's time), especially when translating texts that are repetitive or that use lots of standard phrases and sentence formulations. Producing updates of technical manuals is a typical application of TM systems. Examples of TM systems include:
The European Commission uses TM tools. Have a look at these sites, which contain useful information about translatng in the EU and the tools that are used to speed up workflow:
An example of automatic translations can be found at the Newstran website. This site is extremely useful for locating newspapers in a wide range of languages. You can also locate selected newspapers that have been translated using a Machine Translation system. The quality and accuracy is what you can expect from such systems - but you can get the gist, e.g. "The red-green coalition agreement pushes in the SPD obviously increasingly on criticism" as a rendering of "Die rot-grüne Koalitionsvereinbarung stößt in der SPD offensichtlich zunehmend auf Kritik"
Another approach to translation is the stored phrase bank, for example LinguaWrite, which was aimed at the business user and contained a large database of equivalent phrases and sentences in different languages to facilitate the writing of business letters. LinguaWrite was programmed by Marco Bruzzone in the 1980s and marketed by Camsoft, but it is no longer available and has not been updated. David Sephton's Tick-Tack (Primrose Publishing) adopted a similar approach, beginning as a package consisting of "building blocks" of language for business communication, but it now embraces other topics.
The following examples have often been cited as mistakes made by machine translation (MT) systems. Whether they are real examples or not cannot be verified.
Russian-English:
In a technical text that had
been translated from Russian into English the term water sheep kept appearing.
When the Russian source text was checked it was found that it was actually referring
to a hydraulic ram.
Russian-English:
Idioms are often a problem. It is claimed that the translation of the spirit
is willing but the flesh is weak into Russian ended up as the vodka is
strong but the meat is rotten i.e. after translating the original into
Russian and translating it back into English.
Russian-English:
Another example, similar to the one above, is where out of sight, out of
mind ended up being translated as the equivalent of blind and stupid.
All three of the above examples sound more like mistakes made by human beings or they may just have been invented in order to highlight the shortcomings of MT systems. MT systems do, however, often make mistakes. The Systran MT system, which has been used by the European Commission, translated the English phrase pregnant women and children into des femmes et enfants enceints, which implies that both the women and the children are pregnant. Although it is an interpretation of the original phrase that is theoretically possible, it is also clearly wrong.
Try using an online machine translator to translate a text from English into another language and then back again. The results are often amusing, especially if you are translating nursery rhymes!
(i) Bah, bah, black sheep translated into French and then back again into English, using Babel Fish
English source text:
Bah, bah, black sheep, have you any wool? Yes sir, yes sir, three bags full.
One for the master, one for the dame, and one for the little boy who lives down
the lane.
French translation:
Bah, bah, mouton noir, vous ont n'importe quelles laines ? Oui monsieur, oui
monsieur, trois sacs complètement. Un pour le maître, un pour dame, et un pour
le petit garçon qui vit en bas de la ruelle.
And back into English again:
Bah, bah, black sheep, have you n' imports which wools? Yes Sir, yes Sir, three
bags completely. For the Master, for lady, and for the little boy who lives
in bottom of the lane.
(ii) Humpty Dumpty translated into Italian and then back again into English, using Babel Fish
English source text:
Humpty Dumpty sat on a wall. Humpty Dumpty had a great fall. All the kings
horses and all the kings men couldnt put Humpty together again.
Italian translation:
Humpty Dumpty si è seduto
su una parete. Humpty Dumpty ha avuto una grande caduta. I cavalli di tutto
il re e gli uomini di tutto il re non hanno potuto un Humpty ancora.
And back into English again:
Humpty Dumpty has been based on a wall. Humpty Dumpty has had a great fall.
The horses of all the king and the men of all the king have not been able a
Humpty still.
(iii) Humpty Dumpty translated into Italian and then back again into English, using Google Translate
English source text:
Humpty Dumpty sat on a wall. Humpty Dumpty had a great fall. All the kings
horses and all the kings men couldnt put Humpty together again.
Italian translation:
Humpty Dumpty sedeva su un muro. Humpty Dumpty ha avuto un grande caduta. Tutti
i cavalli del re e tutti gli uomini del re non poteva mettere Humpty di nuovo
insieme.
And back into English again:
Humpty Dumpty sat on a wall. Humpty Dumpty had a great fall. All the king's
horses and all the king's men could not put Humpty together again.
Now, the above is an interesting result! Google Translate used to be a very unreliable MT tool. It drives language teachers mad, as their students often use it to do their homework, e.g. translating from a given text into a foreign language or drafting their own compositions and then translating them. Mistakes made by Google Translate used to be very easy to spot, but (as indicated above in Section 3.1) Google changed its translation engine a few years ago and now uses a Statistical Machine Translation (SMT) approach. The Humpty Dumpty translation back into English from the Italian appears to indicate that Google Translate has matched the whole text and got it right. Clever!
(i) A business text, translated with Google Translate and Babel Fish
Google Translate was used to translate
the following text from German into English:
Die Handelskammer in Saarbrücken hat uns Ihre Anschrift zur Verfügung gestellt.
Wir sind ein mittelgroßes Fachgeschäft in Stuttgart, und wir spezialisieren
uns auf den Verkauf von Personalcomputern.
This was rendered as:
The Chamber of Commerce in Saarbrücken has provided us your address is available.
We are a medium sized shop in Stuttgart, and we specialize in sales of personal
computers. OK, not perfect, but its intelligible.
Babel Fish produced a better version:
The Chamber of Commerce in Saarbruecken put your address to us at the disposal.
We are a medium sized specialist shop in Stuttgart, and we specialize in the
sale of personal computers.
(ii) A journalistic text, translated with Google Translate and Babel Fish
Die deutsche Exportwirtschaft kämpft mit der weltweiten Konjunkturflaute und muss deshalb von den Zeiten zweistelligen Wachstums Abschied nehmen. [Ludolf Wartenberg vom Bundesverband der Deutschen Industrie]
This was rendered by Google Translate
as:
The German export economy is struggling with the global downturn and must therefore
take the times of double-digit growth goodbye. [Ludolf Wartenberg from the Federation
of German Industry]
Not perfect, but its intelligible, and better than the following version that Babel Fish gave me which failed to recognise that Ludolf Wartenberg is a proper name:
The German export trade and industry fights with the world-wide recession and must take therefore from the times of two digit growth parting. [Ludolf waiting mountain of the Federal association of the German industry.]
Contents of Section 4
Computers are normally associated with two standard input devices, the keyboard and the mouse, and two standard output devices, the display screen and the printer. All these restrict language input and output. However, computer programs and hardware devices that enable the computer to handle human speech are now commonplace. All modern computers allow the user to plug in a microphone and record his/her own voice. A variety of other sources of sound recordings can also be used. Storing these sound files is not a problem anymore as a result of the immensely increased capacity and reduced cost of storage media and improved compression techniques that enable the size of sound files to be substantially reduced. For further information on the applications of sound recording and playback technology to CALL see Module 2.2, Introduction to multimedia CALL.
A range of computer software is available for speech analysis. Spoken input can be analysed according to a wide variety of parameters and the analysis can be represented graphically or numerically. Of course, graphic output is not immediately useful for the uninitiated viewer, and hence we are not arguing that this kind of graphical representation will prove useful to the language learner. On the other hand, specialists are well capable of interpreting this speech analysis data.
The information we get from speech analysis has proven very valuable indeed for speech synthesis and speech recognition, which are dealt with in the following two sections.
Speech synthesis describes the process of generating human-like speech by computer. Producing natural sounding speech is a complex process in which one has to consider a range of factors that go beyond just converting characters to sounds because very often there is no one-to-one relation between them. The intonation of particular sentence types and the rhythm of particular utterances also have to be considered.
Currently speech synthesis is far more advanced and more robust than speech recognition (see Section 4.2 below). The naturalness of artificially produced utterances is now very impressive compared to what used to be produced by earlier speech synthesis systems in which the intonation and timing were far from natural and resulted in the production of monotonous, robot-like speech. Many people are now unaware that so-called talking dictionaries use speech synthesis software rather than recordings of human voices. In-car satellite navigation (satnav) systems can produce a range of different types of human voices, both male and female in a number of different languages, and "talk" to the car driver guiding him/her to a chosen destination.
So far, however, speech synthesis has not been as widely used in CALL as speech recognition. This is probably due to the fact that language teachers' requirements regarding the presentation of spoken language are very demanding. Anything that sounds artificial is likely to be rejected. Some language teachers even reject speakers whose regional accent is too far from what is considered standard or received pronunciation.
There is, however, a category of speech synthesis technology known as Text To Speech (TTS) technology that is widely used for practical purposes. TTS software falls into the category of assistive technology, which has a vital role in improving accessiblity for a wide range of computer users with special needs, which is now governed by legislation in the UK. The Special Educational Needs and Disability Act (SENDA) of 2001 covers educational websites and obliges their designers "to make reasonable adjustments to ensure that people who are disabled are not put at a substantial disadvantage compared to people who are not disabled." See JISC's website on Disability Legislation and ICT in Further and Higher Education - Essentials. See the Glossary for definitions of assistive technology and accessiblity.
TTS is important in making computers accessible to blind or partially sighted people as it enables them to "read" from the screen. TTS technology can be linked to any written input in a variety of languages, e.g. automatic pronunciation of words from an online dictionary, reading aloud of a text, etc. These are examples of TTS software:
Google Translate also includes a TTS facility.
Just for fun I entered the phrase "Pas d'elle yeux Rhône que nous" into a couple of French language synthesisers. It's a nonsense sentence in French but it comes out sounding like a French person trying to pronounce a well-known expression in English. Try it!
There are also Web-based tools that enable you to create animated cartoons or movies incorporating TTS, for example:
See Section 2.1.8, Module 1.5, for additional links to animation tools.
|
An excellent tool that helps people with hearing impairments to learn how to articulate is the CSLU Speech Toolkit.
To what extent speech synthesis systems are suitable for CALL is a matter for further discussion. See the article by Handley & Hamel (2005), who report on their progress towards the development of a benchmark for determining the adequacy of speech synthesis systems for use in CALL. The article mentions a Web-based package called FreeText, for advanced learners of French, the outcome of a project funded by the European Commission.
Speech recognition describes the use of computers to recognise spoken words. Speech recognition has not reached such a high level of performance as speech synthesis (see Section 4.1 above), but it has certainly become usable in CALL in recent years. EyeSpeak English is a typical example of the use of speech recognition software for helping students improve their English pronunciation.
Speech recognition is a non-trivial task because the same spoken word does not produce entirely the same sound waves when uttered by different people or even when uttered by the same person on different occasions. The process is complex: the computer has to digitise the sound, transform it to discard unneeded information, and then try to match it with words stored in a dictionary. The most efficient speech recognition systems are speaker-dependent, i.e. they are trained to recognise a particular person's speech and can then distinguish thousands of words uttered by that person.
If one remembers that each of the parameters analysed could have been affected by some speaker-independent background noise or by some idiosyncratic pronunciation features of this particular speaker then it already becomes clear how difficult the interpretation of the analysis data is for a speech recognition program. The problem is compounded by the fact that words are normally not produced in isolation - they are normally uttered in what we call connected speech, i.e. the pronunciation of one word might influence another, and intonation and rhythm will have a bearing on how a single word is going to be pronounced.
Speaker-independent systems are far less efficient, but they are gaining in use in CALL and there are a number of programs that make use of what is known as Automatic Speech Recognition (ASR): see Section 3.4.7, Module 2.2, headed CD-ROMs incorporating Automatic Speech Recognition (ASR). The following information is taken from an article written by Norman Harris of DynEd, a publisher of CALL software incorporating ASR:
Speech recognition technology has finally come of age - at least for language training purposes for young adults and adults. Computer programs that truly "understand" natural speech, the Holy Grail of artificial intelligence researchers, may be a decade or more away, and today's speech recognition programs may be merely pattern matching devices, still incapable of parsing real language, of achieving anything like "understanding," but, nonetheless, they can now provide language students with realistic, highly effective, and motivating speech practice.
The essence of real language is not in discrete single words - language students need to practice complete phrases and sentences in realistic contexts. Moreover, programs which were trained to accept a speaker's individual pronunciation quirks were not ideally suited to helping students move toward more standard pronunciation. These technologies also failed if the speaker's voice changed due to common colds, laryngitis and other throat ailments, rendering them useless until the speaker recovered or retrained the speech engine.
The solution to these problems came with the development of continuous speech recognition engines that were speaker independent. These programs are able to deal with complete sentences spoken at a natural pace, not just isolated words. They require no special hardware, are small enough and fast enough to work on normal PCs, and importantly for the typical language training environment, do not require a training period - they allow a variety of individual language learners working on the same computer to practice speaking English from the first moment they talk into the microphone.
Such flexibility with regard to pronunciation paradigms means that today's speaker-independent speech recognition programs are not ideal for direct pronunciation practice. Nonetheless, exercises which focus on fluency and word order, and with native speaker models which are heard immediately after a student's utterance had been successfully recognized, have been shown to indirectly result in much improved pronunciation. Another trade off is that the greater flexibility and leniency which allows these programs to "recognize" sentences spoken by students with a wide variety of accents, also limits the accuracy of the programs, especially for similar sounding words and phrases. Some errors may be accepted as correct.
Native speakers testing the "understanding" of programs "tuned" to the needs of non-native speakers may be bothered by this, but most teachers, after careful consideration of the different needs and psychologies of native speakers and learners, will accept the trade off. Students do not expect to be understood every time. If they are required occasionally to repeat a sentence which the program has not recognized or which the program has misinterpreted, there may be some small frustration, but language students are much more likely to take this in their stride than would native speakers. On the other hand, if the program does "understand" such students, however imperfect their pronunciation, they typically experience a huge sense of satisfaction, a feel good factor native speakers simply cannot enjoy to anywhere near the same degree. The worst thing for a student is a program that is too demanding of perfection - such programs will quickly lead to student frustration or the kind of embarrassed, hesitant unwillingness to speak English typical of many classrooms. Even if we accept that accuracy needs to be responsive to proficiency in order to encourage students to speak, we must, as teachers, be concerned that errors do not become reinforced.
From Norman Harris: Speech recognition: considerations for use in language training: http://www.dyned.com/about/speech.shtml
Smartphone apps
A recent breakthrough is the implementation of apps such as Apple's Siri on the iPhone 4S and Evi, which is available for the iPhone and the Android. These apps are quite impressive at recognising speech and providing answers to questions submitted by the user. Evi's performance was tested by the author of this paragraph. "She" immediately provided correct answers to these questions submitted by voice input:
In addition, Evi may link to relevant websites that provide further information. Text input is also accepted.
Put in simple terms, a parser is a program that maps strings of a language into its structures. The most basic components needed by a parser are a lexicon containing words that may be parsed and a grammar, consisting of rules which determine grammatical structures. The first parsers were developed for the analysis of programming languages; obviously as artificial, regular languages they present fewer problems than a natural language. It is most useful to think of parsing as a search problem which has to be solved. It can be solved using an algorithm which can be defined as:
[...] a formal procedure that always produces a correct or optimal result. An algorithm applies a step-by-step procedure that guarantees a specific outcome or solves a specific problem. The procedure of an algorithm performs a computation in a finite amount of time. Programmers specify the algorithm the program will follow when they develop a conventional program. (Smith 1990)
Parsing algorithms define a procedure that looks for the optimum combination of grammatical rules that generate a tree structure for the input sentence. How might we define these grammatical rules in a concise way that is amenable to computer processing? A useful construct for our purposes is a so-called context-free grammar (CFG). A CFG consists of rules containing a single symbol on the left-hand side and one or more on the right-hand side. For example, the statement that a sentence can consist of:
a noun phrase and a verb phrase can be expressed by the following rewrite rule
S ® NP VP
This means that a sentence S can be 'rewritten' as a noun phrase NP followed by a verb phrase VP which are in their turn defined in the grammar. A noun phrase, for example, can consist of a determiner DET and a noun N. These symbols are known as non-terminals and the words represented by these symbols are terminal symbols.
Parsing algorithms can proceed top-down or bottom-up. In some cases, top-down and bottom-up algorithms can be combined. Below are simple descriptions of two parsing strategies.
S ® NP VP
and then breaks them down into constituents. The strategy assumes we have an S and tries to fit it in. If we choose to search depth first, then we proceed down one side of the tree at a time. The search will end successfully if it manages to break down the sentence into all its terminal symbols (words).
A bottom up strategy looks at elements of an S and assigns categories to them to form larger constituents until we arrive at an S. If we choose to search breadth first, then we proceed consecutively through each layer and stop successfully once we have constructed a sentence.
Let's look now at one linguistic phenomenon which causes problems for parsers - that of so-called attachment ambiguity. Consider the following sentence:
The man saw the man in the park with a telescope.
Clearly there are a number of possible interpretations, for instance the telescope could be the instrument used to see the second man or the scope of 'in the park with a telescope' could be such that it defines the park, i.e. 'the one with a telescope'. Parser output can be represented as a bracketed list or, more commonly, a tree structure. Here is the output of two possible parses for the sentence above.
Figure 1: Parse Tree Version 1.0
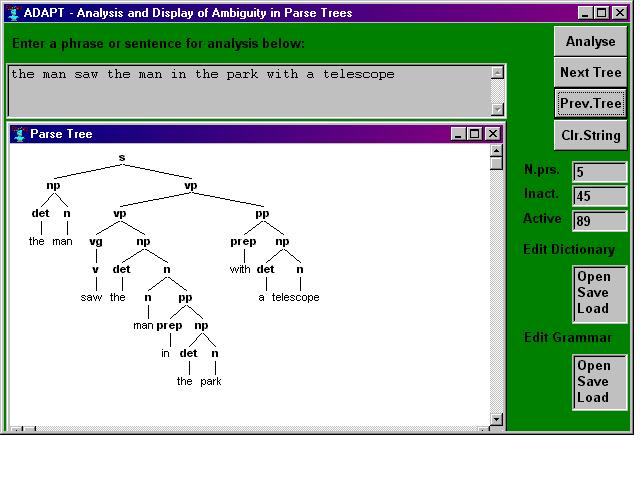
Figure 1: Parse Tree Version 2.0
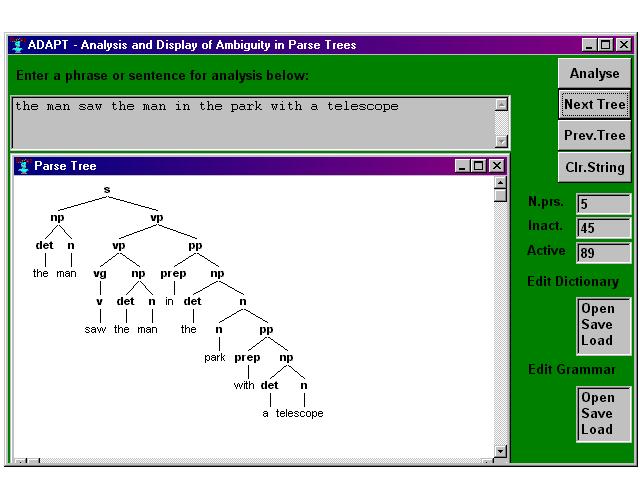
One way of dealing with the problem of sentences which have more than one possible parse is to concentrate on specific elements of the parser input and to not deal with such phenomena as attachment ambiguity. Ideally we expect a parser to successfully analyse a sentence on the basis of its grammar, but often there are problems caused by errors in the text or incompleteness of grammar and lexicon. Also the length of sentences and ambiguity of grammars often make it hard to successfully parse unrestricted text. An approach which addresses some of these issues is partial or shallow parsing. Abney (1997:125) succinctly describes partial parsing thus:
"Partial parsing techniques aim to recover syntactic information efficiently and reliably from unrestricted text, by sacrificing completeness and depth of analysis."
Partial parsers concentrate on recovering pieces of sentence structure which do not require large amounts of information (such as lexical association information); attachment remains unresolved for instance. We can see that in this way parsing efficiency is greatly improved.
Another strategy for analysing language is part-of-speech tagging, in which we do not seek to find larger structures such as noun phrases but instead label each word in a sentence with its appropriate part of speech. To give you some idea of what tagger output looks like, a paragraph of this Web page has been tagged using a tagger developed at the University of Stuttgart: http://www.ims.uni-stuttgart.de/projekte/corplex/TreeTagger/DecisionTreeTagger.html
Here is the original paragraph from Section 3 of this document:
In a transfer model the intermediate representation is language dependent, there being a bilingual module whose function it is to interpose between source language and target language intermediate representations. Thus we cannot say that the transfer module is language independent. The nature of these transfer modules has obvious ramifications for system design in that addition of another language to a system necessitates not only modules for analysis and synthesis but also additional transfer modules, whose number is dictated by the number of languages in the existing system and which would increase polynomially according to the number of additional languages required.
The following table shows the tagger output , and we can see that most of the words have been correctly identified.
Table 1: Tagger output
|
In |
IN |
in |
|
a |
DT |
a |
|
transfer |
NN |
transfer |
|
model |
NN |
model |
|
the |
DT |
the |
|
intermediate |
JJ |
intermediate |
|
representation |
NN |
representation |
|
is |
VBZ |
be |
|
language |
NN |
language |
|
dependent |
JJ |
dependent |
|
, |
, |
, |
|
there |
RB |
there |
|
being |
VBG |
be |
|
a |
DT |
a |
|
bilingual |
JJ |
bilingual |
|
module |
NN |
module |
|
whose |
WP$ |
whose |
|
function |
NN |
function |
|
it |
PP |
it |
|
is |
VBZ |
be |
|
to |
TO |
to |
|
interpose |
VB |
interpose |
|
between |
IN |
between |
|
source |
NN |
source |
|
language |
NN |
language |
|
and |
CC |
and |
|
target |
NN |
target |
|
language |
NN |
language |
|
intermediate |
JJ |
intermediate |
|
representations |
NNS |
representation |
|
. |
SENT |
. |
|
Thus |
RB |
thus |
|
we |
PP |
we |
|
cannot |
VBP |
can |
|
say |
VB |
say |
|
that |
IN |
that |
|
the |
DT |
the |
|
transfer |
NN |
transfer |
|
module |
NN |
module |
|
is |
VBZ |
be |
|
language |
NN |
language |
|
independent |
JJ |
independent |
|
. |
SENT |
. |
|
The |
DT |
the |
|
nature |
NN |
nature |
|
of |
IN |
of |
|
these |
DT |
these |
|
transfer |
NN |
transfer |
|
modules |
NNS |
module |
|
has |
VBZ |
have |
|
obvious |
JJ |
obvious |
|
ramifications |
NNS |
ramification |
|
for |
IN |
for |
|
system |
NN |
system |
|
design |
NN |
design |
|
in |
IN |
in |
|
that |
DT |
that |
|
addition |
NN |
addition |
|
of |
IN |
of |
|
another |
DT |
another |
|
language |
NN |
language |
|
to |
TO |
to |
|
a |
DT |
a |
|
system |
NN |
system |
|
necessitates |
VBZ |
necessitate |
|
not |
RB |
not |
|
only |
JJ |
only |
|
modules |
NNS |
module |
|
for |
IN |
for |
|
analysis |
NN |
analysis |
|
and |
CC |
and |
|
synthesis |
NN |
synthesis |
|
but |
CC |
but |
|
also |
RB |
also |
|
additional |
JJ |
additional |
|
transfer |
NN |
transfer |
|
modules |
NNS |
module |
|
, |
, |
, |
|
whose |
WP$ |
whose |
|
number |
NN |
number |
|
is |
VBZ |
be |
|
dictated |
VBN |
dictate |
|
by |
IN |
by |
|
the |
DT |
the |
|
number |
NN |
number |
|
of |
IN |
of |
|
languages |
NNS |
language |
|
in |
IN |
in |
|
the |
DT |
the |
|
existing |
JJ |
existing |
|
system |
NN |
system |
|
and |
CC |
and |
|
which |
WDT |
which |
|
would |
MD |
would |
|
increase |
VB |
increase |
|
polynomially |
RB |
<unknown> |
|
according |
VBG |
accord |
|
to |
TO |
to |
|
the |
DT |
the |
|
number |
NN |
number |
|
of |
IN |
of |
|
additional |
JJ |
additional |
|
languages |
NNS |
language |
|
required |
VBN |
require |
|
. |
SENT |
. |
As with partial parsing, we are not trying to find correct attachments and since it is a limited task the success rate is quite high. The information derived from tagging can itself have input into partial parsing or into improving the performance of traditional parsers. Some of the decision task as to what is the correct part of speech to assign to a word is based on the probability of two or three word sequences (bigrams and trigrams) occurring, even where words can be assigned more than one part of speech. For instance, in our example tagged text the sequence 'the transfer module' occurs. Transfer is of course also a verb, but the likelihood of a determiner (the) being followed by a verb is lower than the likelihood of a determiner noun sequence.
For more detailed discussion see Chapter 10 of Manning & Schütze (1999).
See also the Visual Interactive Syntax Learning (VISL) website. An online parser and a variety of other tools concerned with English grammar, including games and quizzes, can be found here. The site also contains a section on Machine Translation and links to corpora in different languages: http://visl.sdu.dk
Of course, in CALL we are dealing with texts that have been produced by language learners at various levels of proficiency and accuracy. It is therefore reasonable to assume that the parser has to be prepared to deal with linguistic errors in the input. One thing we could do is to complement our grammar for correct sentences with a grammar of incorrect sentences - an error grammar, i.e. we capture individual and/or typical errors in a separate rule system. The advantage of this error grammar approach is that the feedback can be very specific and is normally fairly reliable because this feedback can be attached to a very specific rule. The big drawback, however, is that individual learner errors have to be anticipated in the sense that each error needs to be covered by an adequate rule.
However, as already stated it is not only in texts that have been produced by language learners that we find erroneous structures. Machine translation is facing similar problems. Dina & Malnati review approaches "concerning the design and the implementation of grammars able to deal with 'real input'." (Dina & Malnati 1993:75). They list four approaches:
Consequently, the "most plausible interpretation of a [...] sentence is the one which satisfies the largest number of constraints." (Dina & Malnati 1993:80)
They conclude that "weak constraint-based parsing has proven to be useful in increasing the robustness of an NLP system" (Dina & Malnati 1993:88), basing their conclusion on the following advantageous features of the approach: non-redundancy, built-in preference mechanism, globality, efficiency, linguistic flexibility.
We have seen in Section 3 that Machine Translation (MT) and the political and scientific interest in machine translation played a significant role in the acceptance (or non-acceptance) as well as the general development of Human Language Technologies.
By 1964, however, the promise of operational MT systems still seemed distant and the sponsors set up a committee, which recommended in 1966 that funding for MT should be reduced. It brought to an end a decade of intensive MT research activity. (Hutchins 1986:39)
It is then perhaps not surprising that the mid-1960s saw the birth of another discipline: Computer Assisted Language Learning (CALL). The PLATO project, which was initiated at the University of Illinois in 1960, is widely regarded as the beginning of CALL - although CALL was just part of this huge package of general Computer Assisted Learning (CAL) programs running on mainframe computers. PLATO IV (1972) was probably the version of this project that had the biggest impact on the development of CALL (Hart 1995). At the same time, another American university, Brigham Young University, received government funding for a CALL project, TICCIT (Time-Shared Interactive, Computer Controlled Information Television) (Jones 1995). Other well-known and still widely used programs were developed soon afterwards:
In the UK, John Higgins developed Storyboard in the early 1980s, a total Cloze text reconstruction program for the microcomputer (Higgins & Johns 1984:57). (Levy 1997:24-25) describes how other programs extended this idea further. See Section 8.3, Module 1.4, headed Total text reconstruction: total Cloze, for further information on total Cloze programs.
In recent years the development of CALL has been greatly influenced by the technology and by our knowledge of and our expertise in using it, so that not only the design of most CALL software, but also its classification has been technology-driven. For example, Wolff (1993:21) distinguished five groups of applications:
See also Section 3, Module 1.4, headed CALL typology, phases of CALL, CALL software evaluation.
The late 1980s saw the beginning of attempts which are mostly subsumed under Intelligent CALL (ICALL), a "mix of AI [Artificial Intelligence] techniques and CALL" (Matthews 1992b:i). Early AI-based CALL was not without its critics, however:
In going down this dangerous path, it seems to me that we are indeed seeking to marginalise humanity and create a race of computerised monsters which, when the power of decision-making is given into their hands, will decree that the human race, with its passions, inconsistencies, foibles and frailties, should be declared redundant, and that the intelligent machine shall inherit the earth. And that, fundamentally, is why my initial enthusiasm has now turned so sour. (Last 1989:153)
For a more up-to-date and positive point of view of Artifical Intelligence, see Dodigovic (2005).
Bowerman (1993:31) notes: "Weischedel et al. (1978) produced the first ICALL [Intelligent CALL] system which dealt with comprehension exercises. It made use of syntactic and semantic knowledge to check students' answers to comprehension questions."
As far as could be ascertained, this was just the early swallow that did not create a summer. Krüger-Thielmann (1992:51ff.) lists and summarises the following early projects in ICALL: ALICE, ATHENA, BOUWSTEEN & COGO, EPISTLE, ET, LINGER, VP2, XTRA-TE, Zock.
Matthews (1993:5) identifies Linguistic Theory and Second Language Acquisition Theory as the two main disciplines which inform Intelligent CALL and which are (or will be) informed by Intelligent CALL. He adds: "the obvious AI research areas from which ICALL should be able to draw the most insights are Natural Language Processing (NLP) and Intelligent Tutoring Systems (ITS)" (Matthews1993:6). Matthews shows that it is possible to "conceive of an ICALL system in terms of the classical ITS architecture" (ibid.). The system consists of three modules - expert, student and teacher module - and an interface. The expert module is the one that "houses" the language knowledge of the system. It is this part which can process any piece of text produced by a learner - in an ideal system. This is usually done with the help of a parser of some kind:
The use of parsers in CALL is commonly referred to as intelligent CALL or 'ICALL'; it might be more accurately described as parser-based CALL, because its 'intelligence' lies in the use of parsing - a technique that enables the computer to encode complex grammatical knowledge such as humans use to assemble sentences, recognise errors, and make corrections. (Holland et al. 1993:28)
This notion of parser-based CALL not only captures the nature of the field much better than the somewhat misleading term "Intelligent CALL" (Is all other CALL un-intelligent?), it also identifies the use of Human Language Technologies as one possible approach in CALL alongside others such as multimedia-based CALL and Web-based CALL and thus identifies parser-based CALL as one possible way forward for CALL. In some cases, the (technology-defined) borders between these sub-fields of CALL are not even clearly identifiable, as we will see in some of the projects mentioned in the following paragraphs.
To exemplify recent advances in the use of sophisticated human language technology in CALL, let us have a look at some of the projects that were presented at two conferences in the late 1990s. The first one is the Language Teaching and Language Technology conference in Groningen in 1997 (Jager et al. 1998).
Carson-Berndsen (1998) discussed APron, Autosegmental Pronunciation Teaching, which uses a phonological knowledge base and generates "event structures for some utterance" (op.cit.:15) and can, for example, visualise pronunciation processes of individual sounds and well-formed utterances using an animated, schematic vocal tract. Witt & Young (1998), on the other hand, are concerned with assessing pronunciation. They implemented and tested a pronunciation scoring algorithm which is based on speech recognition (see Section 4.2) and uses hidden Markov models. "The results show that - at least for this setup with artificially generated pronunciation errors - the GOP [goodness of pronunciation] scoring method is a viable assessment tool." A third paper on pronunciation at this conference, by Skrelin & Volskaja (1998) outlined the use of speech synthesis (see Section 4.1) in language learning and lists dictation, distinction of homographs, a sound dictionary and pronunciation drills as possible applications.
A number of papers, presented at this conference, were based on results of the GLOSSER project, an EU-funded Copernicus project that aimed to demonstrate the use of language processing tools: Locolex, a morphological analyser and part-of-speech disambiguation package from Rank Xerox Research Centre, relevant electronic dictionaries, such as Hedendaag Frans, and access to bilingual corpora. "The project vision foresees two main areas where GLOSSER applications can be used. First, in language learning and second, as a tool for users that have a bit of knowledge of a foreign language, but cannot read it easily or reliably" (Dokter & Nerbonne 1998:88). Dokter & Nerbonne report on the French-Dutch demonstrator running under UNIX. The demonstrator:
Roosma & Prószéky (1998) draw attention to the fact that GLOSSER works with the following language pairs: English-Estonian-Hungarian, English-Bulgarian, French-Dutch and describe a demonstrator version running under Windows. Dokter et al (1998) conclude in their user study "that Glosser-RuG improves the ease with which language students can approach a foreign language text" (Dokter et al. 1998:175).
Other CALL projects that explore the use of language processing technology are RECALL (Murphy et al. 1998; Hamilton 1998), a "knowledge-based error correction application" (Murphy et al. 1998:62) for English and German, and the development of tools for learning Basque as a foreign language (Diaz de Ilarranza et al. 1998). The latter project relies on a spellchecker, morphological analyser, syntactic parser and a lexical database for Basque, and the authors report on the development of an interlanguage model.
At another conference (UMIST, May 1998), which brought together a group of researchers who are exploring the use of HLT in CALL software, Schulze et al. (1999) and Tschichold (1999) discussed strategies for improving the success rate of grammar checkers. Menzel & Schröder (1999) described error diagnosis in a multi-level representation. The demonstration system captures the relations of entities in a simple town scenery. The available syntactic, semantic and pragmatic information is checked simultaneously for constraint violations, i.e. errors made by the language learners. Visser (1999) introduced CALLex, a program for learning vocabulary based on lexical functions. Diaz de Ilarraza et al. (1999) described aspects of IDAZKIDE, a learning environment for Spanish learners of Basque. The program contains the following modules: wide-coverage linguistic tools (lexical database with 65,000 entries; spell checker; a word form proposer and a morphological analyser), an adaptive user interface and a student modelling system. The model of the students' language knowledge, i.e. their interlanguage, is based on a corpus analysis (300 texts produced by learners of Basque). Foucou & Kübler (1999) presented a Web-based environment for teaching technical English to students of computing. Ward et al. (1999) showed that Natural Language Processing techniques combined with a graphical interface can be used to produce meaningful language games. Davies & Poesio (1998) reported on tests of simple CALL prototypes that have been created using CSLUrp, a graphical authoring system for the creation of spoken dialogue systems. They argue that since it is evident that today's dialogue systems are usable in CALL software, it is now possible and necessary to study the integration of corrective feedback in these systems. Mitkov (1998) outlined early plans for a new CALL project, The Language Learner's Workbench. It is the aim of this project to incorporate a number of already available HLT tools and to package them for language learners.
These examples of CALL applications that make use of Human Language Technologies are by no means exhaustive. They not only illustrate that research in HLT in CALL is vibrant, but also that HLT has an important contribution to make in the further development of CALL. Of course, both disciplines are still rather young and many projects in both areas, CALL and HLT, have not even reached the stage of the implementation of a fully functional prototype yet. However, successful CALL projects in which utilise the advantages of HLT (and avoid some of the pitfalls) are testimony to the fact that these new language technologies have a lot to offer for the development of CALL software that learners can use more easily, more effectively and more naturally.
A number of CALL packages that make use of speech recognition have reached the commercial market and are being used successfully by learners all over the world (see Section 4.2). Speech synthesis, certainly at word level, has achieved a clarity of pronunciation that makes it a viable tool for language learning (see Section 4.1). Many popular electronic dictionaries now incorporate speech synthesis systems. Part-of-speech taggers have reached a level of accuracy that makes them usable in the automatic pre-processing of learner texts. Morphological analysers for a number of languages automatically provide grammatical information on vocabulary items in context and make automatic dictionary look-ups of inflected or derived word forms possible. Parsing technology is capable of being a backbone of a grammar checker for foreign-language learners, a grammar checker that, of course, is far from perfect, but that is clearly superior to many of the currently commercially available grammar checkers that are mainly based on simple pattern matching and not on linguistic methods.
This progress in HLT and CALL has mainly been possible as the result of our better understanding of the structures of language - our understanding of linguistics. The lack of linguistic modelling and the insufficient deployment of Natural Language Processing techniques has sometimes been given as one reason for the lack of progress in some areas of CALL: see, for example, Levy (1997:3), citing Kohn (1994).
[...] Kohn suggests that current CALL is lacking because of poor linguistic modelling, insufficient deployment of natural language processing techniques, an emphasis on special-purpose rather than general-purpose technology, and a neglect of the 'human' dimnesion of CALL (Kohn 1994:32).
The examples in the previous section have shown that it is possible to apply certain linguistic theories (e.g. phonology and morphology) to Human Language Technologies and implement this technology in CALL software. However, opponents of a parser-based approach in CALL claim that "AI architecture is still a long way from being able to create anything close to mirror the complex system of communication instantiated in any human language and is, hence, unable to introduce any qualitative leap in the design of CALL programs" (Salaberry 1996:11). Salaberry backs up this claim by adding that "[t]he most important reason for this failure [of ICALL] is that NLP (Natural Language Processing) programs - which underlie the development of ICALL - cannot account for the full complexity of natural human languages" (Salaberry 1996:12). This is, of course, true. However, it does not mean that interesting fragments or aspects of a given language cannot be captured by a formal linguistic theory and hence implemented in a CALL application. In other words, if one cannot capture the German language in its entirety in order to implement this linguistic knowledge in a computer program, this does not mean that one cannot capture interesting linguistic phenomena of that language. For instance, the structure of German words, their morphology, can be described in a way the computer "understands" and this knowledge provides a solid basis for a variety of CALL applications (identifying different grammatical endings, practising the inflection of German words in context, some help with proof-reading documents etc.). This means even if we are only able to describe a fragment of a given language adequately we can still make very good use of this description in computer applications for language learning. This is very important, because it will always be the case that we cannot describe a living language completely - how could we: language is constantly being changed in communication, we adapt it to developing and changing needs - so we need to make good use of the knowledge we have about certain aspects or fragments of language.
What is the kind of knowledge we ought to have about language before we can attempt to produce an HLT tool that can be put to effective use in CALL? Let us look at one particular aspect of language - grammar. In recent years, the usefulness of conscious learning of grammar has been discussed time and again, very often in direct opposition to what has been termed "the communicative approach". Goodfellow & Metcalfe (1997), in a special issue of ReCALL on grammar in Computer Assisted Language Learning, argue that " [...] the contributors to this edition of ReCALL have shown that, through CALL, grammar can be taught without sterility but with sensitivity, richness and enjoyment." (ibid.:6) This assumption leads to the question of what role exactly the computer (program) has to play in a sensitive, rich and enjoyable grammar-learning process. The diversity of approaches outlined in this special issue of ReCALL on grammar illustrates that there are many different roads to successful grammar learning that will need to be explored. In this module, only the example of parser-based CALL will be discussed. Let us take a grammar checker for language learners as a specific example in point. This grammar checker could then be integrated into a CALL program, a word-processor, an email editor, a Web page editor etc. The design of such a grammar checker is mainly based on findings in theoretical linguistics and second language acquisition theory.
Let us start with second language acquisition theory. Research in second language acquisition has proved that grammar learning can lead to more successful language acquisition. Ellis (1994) relies on a study by Long (1991) and argues that teaching grammar with "focus on forms" is counter-productive, "while that [approach] which allows for a focus on form results in faster learning and higher levels of proficiency." (Ellis 1994:639) The distinction between "forms" and "form" can be explained as the distinction between grammar drill which concentrates on individual forms on the one hand, and conscious reflection during or at the end of a text production process which concentrates on the form of the text - concentrates on the "how" of text production as opposed to the "what". Assuming that the overall text production process is embedded in an authentic communicative task, then the reflection stage requires the learner to monitor the linguistic aspect of the text production not only the content or the communicative function, i.e. during the reflection stage the learners focus on the form of the (written) text. Here learners have the opportunity to correct grammatical errors and mistakes that they have made while concentrating on the subject matter and the communicative function of the text. It is at this stage that a grammar checker for language learners can provide useful and stimulating guidance.
In order to ascertain the computational features of such a grammar checker, let us first consider what exactly we mean by "grammar" in a language learning context. Helbig discusses possible answers to this question from the point of view of the teaching and learning of foreign languages in general:
As a starting point for answering our question concerning the relevance (and necessity) of grammar in foreign language teaching we used a differentiation of what was and is understood by the term "grammar":
Helbig identifies further a Grammar B1 and a Grammar B2 - the former being a linguistic grammar and the latter being a learner grammar. Taking into consideration that it is possible to differentiate Grammar B1 even further, Helbig supposes the existence of grammars B1a - the linguistic description of the foreign language; B1b - the linguistic description of the mother tongue; and B1c - the confrontation of mother tongue and foreign language. The description of grammar B1c is a literal translation of Helbig's wording - in the terminology used now, the term "interlanguage" appears to be the most appropriate.
The application of Helbig's grammar classification to CALL produces the following results:
Consequently, Grammar B in its entirety and Grammar C will have to be considered first and foremost when developing the grammar checker. The question then arises: If Grammar A provides the linguistic data for the parser developer, how can we "feed" these different grammars into a computer program?
The computer requires that any grammar which we intend to use in any program (or programming language, for that matter) be mathematically exact. Grammars which satisfy this condition are normally referred to as formal grammars. The mathematical description of these grammars uses set theory. Therefore, a language L is said to have a vocabulary V. The possible strings which could be constructed using the vocabulary V are then called the closure of V and will be labelled V*. If there were no restrictions on how to construct strings, the number of possible strings is infinite. This becomes clear when one considers that each vocabulary item of V could be repeated infinitely in order to construct a string. However, as language learners in particular know any language L adheres to a finite set of (grammar) rules. In other words, L contains all those strings of the closure V* that satisfy the grammar rules of L.
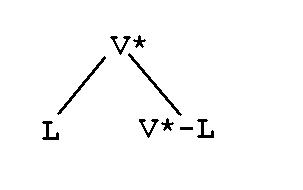
Note that both V* (the number of strings that could be constructed using vocabulary V) and L (the number of possible sentences in a language are infinite. Although mathematically, it cannot be proven that consequently V*-L (the number of possible ungrammatical sentences) is infinite as well, we better assume it is. This explains why grammar teaching software that attempts to anticipate possible incorrect answers can only do this successfully if the answer domain is severely restricted and the anticipation process will therefore much simpler. Of course, what any language teacher does when helping learners to correct a text, which they have just produced, is to help them to identify all correct sentences (the ones in L) and identify all ill-formed sentences (the ones in V*-L); and then to encourage, explain, demonstrate the transformation of the latter into a corresponding well-formed sentence. Could a computer program perform this task - a task based on infinite possibilities? Yes, it could - but not based on infinite possibilities. That is why it will be necessary to look for an approach which is based on a finite set of possibilities, which can then be pre-programmed. Let us therefore consider L the set of strings that can be constructed using the (formal) grammar G. A formal grammar can be defined as follows (see e.g. Allen 1995):
G (VN, VT, R, S)
Grammar G is a function with four lists as arguments: VN is a list of non-terminal symbols such as NP (noun phrase) and VP (verb phrase); VT is a list of terminal symbols, i.e. words; R stands for the set of grammatical rules which describe the formation of non-terminal symbols; and S is a start node. And here we are already dealing with sets which have a finite number of members. The number of grammatical rules is fairly limited. This is certainly the case when we only consider the basic grammar rules of a language that will have to be learned by the intermediate to early advanced learner. (Note here what we said earlier about Grammar B2 - the learner grammar: It was only a subset of Grammar 1 - the linguistic grammar.)
Formal grammars have been used in a number of CALL projects. Matthews (1993) continues his discussion of grammar frameworks for CALL which he started in 1992 (Matthews 1992a). He lists eight major grammar frameworks that have been used in CALL:
Of course, these are only some examples. More recently, Tschichold et al. (1994) reported on a prototype for correcting English texts produced by French learners. This system relies on a number of different finite state automata for pre-processing, filtering and detecting (Tschichold et al.1994). Brehony & Ryan (1994) report on "Francophone Stylistic Grammar Checking (FSGC) using Link Grammars". They adapted the post-processing section of an existing parser so that it would detect stylistic errors in English input produced by French learners.
Matthews adds, after having listed the different approaches, that "the [...] list does not include some of the frameworks [...] for instance, Categorial Grammar, Generalised Phrase Structure Grammar (GPSG), and Head-Driven Phrase Structure Grammar (HPSG)" (Matthews 1993:9). His plea is for the use of the PPT (Principles and Parameters Theory (Chomsky 1986) as a grammar framework for CALL applications, basing his judgement on three criteria: computational effectiveness, linguistic perspicuity and acquisitional perspicuity (Matthews 1993:9). In later parts of his paper, Matthews compares rule- and principle-based frameworks using DCGs (Definite Clause Grammars) as the example for the latter. He concludes that principle-based frameworks (and consequently principle-based parsing) are the most suitable grammar frameworks for what he calls Intelligent CALL.
Recently, other unification-based grammar frameworks not included in Matthews' list have been used in CALL. Hagen, for instance, describes "an object-oriented, unification-based parser called HANOI" (Hagen 1995) which uses formalisms developed in Head-Driven Phrase Structure Grammar (HPSG). He quotes Zajac :
Combining object-oriented approaches to linguistic description with unification-based grammar formalisms [...] is very attractive. On one hand, we gain the advantages of the object-oriented approach: abstraction and generalisation through the use of inheritance. On the other hand, we gain a fully declarative framework, with all the advantages of logical formalisms [...]
Of course, not even this extended list is comprehensive - at best it could be described as indicative of the variety of linguistic approaches used in parser-based Computer Assisted Language Learning and, in particular, in the field of grammar checking. At the end of this short excursion into formal grammar(s) it can be concluded that any CALL grammar checker component needs as its foundation a formal grammar describing as comprehensively as possible the knowledge we have about the target language grammar. This was the grammar that Helbig (1975) refers to as Grammar B1a. But what part do the other grammars play in a CALL environment?
Let us stay with the example of a parser-based grammar checker for language learners. Comparing such a grammar checker to commercially available grammar checkers reveals two major differences: a parser-based grammar checker attempts to provide feedback on errors typically made by foreign language learners and does not function as a style checker like many commercial grammar checkers do (e.g. they notify the text producer of the over-use of passive constructions, point out sentences which are either too complex or too long). Hence, the provision of adequate feedback on the morpho-syntactic structure of parts of the text produced by learners is the most important task for this parser-based grammar checker. Let us therefore consider the place of feedback provision within a parser grammar.
In a first approximation, we could say that feedback shows the relation between the produced construction in V*-L and the intended construction in L. In other words, as a good teacher would do - the grammar checker would offer advice on how to change an ungrammatical structure into a corresponding grammatically well-formed structure. As stated earlier this approach would be based on an infinite number of construction possibilities. Therefore, the provision of adequate feedback and help to the learner appears to be difficult if not impossible. However, it has been indicated above that feedback could be linked to the finite sets on which the formal grammar relies. How can this be done? Each member of the three sets which will have to be considered here. The non-terminal symbols like NP and VP, the words and the set of morpho-syntactic rules carry certain features that determine their behaviour in a sentence and determine their relation to other signs within the sentence. For instance, a masculine article only unifies with a masculine noun, a noun phrase in nominative indicates its willingness to act as the grammatical subject of a sentence, the separable prefix of a German main verb prefers to occupy the sentence-final position in a verb-second clause etc. These features which restrict what the text producer can do with a given (terminal or non-terminal) symbol in a sentence and under what conditions a particular grammatical rule has to be applied will be labelled constraints.
Let us return to our provisional description of feedback, which can now be formulated more precisely.
Feedback shows the relation
Firstly, our better understanding of feedback shows that Helbig's notion of different grammar systems in the learning and teaching of a foreign language is not only applicable to (parser-based) CALL, but provides useful information for authors of software that aims to provide learner support in grammar acquisition. And secondly, this above description of feedback given by a grammar checker which is based on a modified parser shows that it is possible to construct tools that support the focus on form by learners during the reflection stage of a text production process. Even if the grammar checker were only to detect a small number of morpho-syntactic errors, this would be beneficial for the learners as long as they were aware of the limitations of this CALL tool. On the other hand, the feedback description contains still a number of question marks in parentheses after some of the important keywords - whether the intended aims of grammar checking can be achieved can only be validated through the use and thorough testing of such a grammar checker. We should better not make any such assumption (in the scientific sense - we do hope for these improvements, of course) and better wait until such a parser-based grammar checker is actually tested in a series of proper learning experiments.
Let us now leave the discussion of some of the underlying linguistics behind and discuss the role of parser-based applications in language learning.
Natural language parsers take written language as their input and produce a formal representation of the syntactic and sometimes semantic structure of this input. The role they have to play in computer-assisted language learning has been under scrutiny in the last decade: (Matthews 1992a); (Holland et al. 1993); (Nagata 1996). See also Heift (2001).
Holland et al. discussed the "possibilities and limitations of parser-based language tutors" (Holland et al. 1993:28). Comparing parser-based CALL to what they label as conventional CALL they come to the conclusion that:
[...] in parser-based CALL the student has relatively free rein and can write a potentially huge variety of sentences. ICALL thus permits practice of production skills, which require recalling and constructing, not just recognising [as in conventional CALL], words and structures. (Holland et al.1993:31)
However, at the same time, parsing imposes certain limitations. Parsers tend to concentrate on the syntax of the textual input, thus "ICALL may actually subvert a principal goal of language pedagogy, that of communicating meanings rather than producing the right forms" (Holland et al.1993:32). This disadvantage can be avoided by a "focus on form" which is mainly achieved by putting the parser/grammar checker to use within a relevant, authentic communicative task and at a time chosen by and convenient to the learner/text producer.
Juozulynas (1994) evaluated the potential usefulness of syntactic parsers in error diagnosis. He analysed errors in an approximately 400 page corpus of German essays by American college students in second-year language courses. His study shows that:
[...] syntax is the most problematic area, followed by morphology. These two categories make up 53% of errors [...] The study, a contribution to the error analysis element of a syntactic parser of German, indicates that most student errors (80%) are not of semantic origin, and therefore, are potentially recognisable by a syntactic parser. (Juozulynas 1994:5)
Juozulynas adapted a taxonomic schema by Hendrickson which comprises four categories: syntax, morphology, orthography, lexicon. Juozulynas' argument for splitting orthography into spelling and punctuation is easily justified in the context of syntactic parsing. Parts of punctuation can be described by using syntactic bracketing rules, and punctuation errors can consequently be dealt with by a syntactic parser. Lexical and spelling errors form, according to Juozulynas, a rather small part of the overall number of learner errors. Some of these errors will, of course, be identified during dictionary look-up, but if words that are in the dictionary are used in a nonsensical way, the parser will not recognise them unless specific error rules (e.g. for false friends) are built in. It can be assumed, however, that the parser is used in conjunction with a spellchecker (so most of the orthographic errors could be eliminated before the parser starts its analysis) and that learners have good knowledge of what they want to say (to avoid many errors of a semantic nature). Consequently, a parser-based CALL application can play a useful role in detecting many of the morpho-syntactic errors which constitute a high percentage of learner errors in freely produced texts.
Nevertheless, the fact remains:
A second limitation of ICALL is that parsers are not foolproof. Because no parser today can accurately analyse all the syntax of a language, false acceptance and false alarms are inevitable. (Holland et al. 1993:33)
This is something not only developers of parser-based CALL, but also language learners using such software have to take into account. In other words, this limitation of parser-based CALL has to be taken into consideration during the design and implementation process and when integrating this kind of CALL software in the learning process.
A final limitation of ICALL is the cost of developing NLP systems. By comparison with simple CALL, NLP development depends on computational linguists and advanced programmers as well as on extensive resources for building and testing grammars. Beyond this, instructional shells and lessons must be built around NLP, incurring the same expense as developing shells and lessons for CALL. (Holland et al. 1993:33)
It is mainly this disadvantage of parser-based CALL that explains the lack of commercially available (and commercially viable) CALL applications which make good use of HLT. However, it is to be hoped that this hurdle can be overcome in the not too distant future because sufficient expertise in the area has accumulated over recent years. More and more computer programs make good use of this technology, and many of these have already "entered" the realm of computer-assisted language learning, as can be seen from the examples in the previous section.
Holland et al. (1993) answer their title question "What are parsers good for?" on the basis of their own experience with BRIDGE, a parser-based CALL program for American military personnel learning German, and on the basis of some initial testing with a small group of experienced learners of German. They present the following points:
Given that we would like to harness the advantages of parser-based CALL, how do we take the limitations into consideration in the process of designing and implementing a parser-based CALL system? What implications does the use of parsing technology have for human-computer interaction?
This limitation [that parsers are not foolproof] leads to a second disadvantage of ICALL: Because parsers give the illusion of certainty, their feedback may at best confuse students [...] By contrast, in traditional CALL the very rigidity of the response requirement guarantees certainty[...]. [I]n discourse analytic terms (Grice 1975), the nature of the contract between student and CALL tutor is straightforward, respecting the traditional assumption that the teacher is right, whereas the ICALL contract is less well defined. (Holland et al. 1993:33f.)
The rigidity of traditional CALL in which the program controls the linguistic input by the learner to a very large extent has often given rise to a criticism of CALL which accuses CALL developers and practitioners of relying on behaviourist programmed instruction. If one wants to give learners full control over their linguistic input, for example, by relying on parsing technology, what are then the terms according to which the communicative interaction of computer (program) and learner can be defined? The differences between humans and machines have obviously to be taken into consideration in order to understand the interaction of learners with CALL programs:
These differences between humans and machines can for our purposes, i.e. the theoretical description of human-computer interaction, be legitimately reduced to the distinction between actions and operations as is done in Activity Theory. The main point of this theory for our consideration here is that communicative activities can be divided into actions which are intentional, i.e. goal-driven; and these can be sub-divided into operations which are condition-triggered. These operations are normally learnt as actions. In the example referred to in the quotation above, the gear-switching is learnt as an action. The learner-driver is asked by the driving instructor to change gear and this becomes the goal of the learner. Once the learner-driver has performed this action a sufficient number of times, this action becomes more and more automated and in the process loses more and more of its intentionality. A proficient driver might have the goal to accelerate the car which will necessitate switching into higher gear, but this is now triggered by a condition (the difference between engine speed and speed of the car). It can thus be argued that humans learn to perform complex actions by learning to perform certain operations in a certain order. Machines, on the other hand, are only made to perform certain (sometimes rather complex) operations. Sequences of such operations can be performed by sophisticated machines like computers in rapid succession (or with powerful computers even in parallel), but each and every one of them is initialised by a condition (e.g. a mouse-click, keyboard input) and they are not subordinated to an intention, so they cannot be described as actions (Schmitz 1992:169).
This has some bearing on our understanding of the human-computer interaction that takes place when a learner uses language-learning software. When, for instance, the spell checker is started in a word-processing package, the software certainly does not have 'proof-read' the learner's document. The computer just responds to the clicking of the spellchecker menu item and performs the operation of checking the strings in the document against the entries in a machine dictionary. The result of the comparison triggers the next operation: if an identical string has been found in the dictionary, the next string from the document is being compared; if an identical string could not be found in the dictionary, similar strings will be selected from the dictionary according to an established algorithm and these will be displayed to the user as spelling alternatives. For the computer user (in our case a learner), it might look like the computer is proof-reading the document. Normally, one only realises that no "proper" document checking is going on if a correctly spelled word is not found in the dictionary or nonsensical alternatives are given for a simple spelling error.
Person X interacts with Person Y in that he observes Person Y's action, reasons about the likely intention for that action and reacts according to this assumed intention. It appears to be the case that many learners transfer this approach to the interaction with a computer in a language learning situation, i.e. they interpret the sequence of operations performed by the computer as an action, reason about the "intention" of the computer and react accordingly. This, for example, explains why many learners get just as frustrated when an answer they believe to be right is rejected by the computer as they would get if it were rejected by their tutor.
Of course, an ideal computer-assisted language learning system would avoid such pitfalls and not reject a correct response or overlook an incorrect one. Since any existing system can only approximate to this ideal, researchers and developers in parser-based CALL can only attempt to build systems that can perform complex structured sequences of (linguistic) operations so that learners can interact meaningfully and successfully with the computer.
Progress is, however, being made and there are examples of practical applications: e.g. Grammatica, a package that integrates a parser into a word-processor: http://www.ultralingua.com. Grammatica is able to identify parts of speech in English and French with a fair degree of accuracy and show, for example, how verbs are conjugated in different tenses and how plurals of nouns are formed.
Corpus linguistics has traditionally been part of HLT, but it is now such a vast area of research and activity that it merits a module of its own: Module 3.4.
Abeillé A. (1992) "A lexicalised tree adjoining grammar for French and its relevance to language teaching". In Swartz M. & Yazdani M. (eds.) Intelligent tutoring systems for foreign language learning: the bridge to international communication, Berlin: Springer-Verlag.
Abney S. (1997) "Part-of-speech tagging and partial parsing". In Young S. & Bloothooft G. (eds.) Corpus-based methods in language and speech processing, Dordrecht: Kluwer AcademicPublishers.
Allen J. (1995) Natural language understanding, New York: John Benjamins Publishing Company.
Alwang G. (1999) "Speech recognition", PC Magazine, 10 November 1999.
Antos G. (1982) Grundlagen einer Theorie des Formulierens. Textherstellung in geschriebener und gesprochener Sprache, Tübingen: Niemeyer.
Arnold D., Balkan. L, Meijer S., Humphreys R. L. & Sadler L. (1994) Machine Translation: an introductory guide, Manchester: NEC Blackwell.
Bellos
D. (2011) Is that a fish in your ear? Translation and the meaning of everything,
Harlow: Penguin / Particular Books.
Bennett P. (1997) Feature-based approaches to grammar, Manchester: UMIST, Unpublished Manuscript.
Bennett P. & Paggio P. (eds.) (1993) Preference in EUROTRA, Luxembourg: European Commission.
Bloothooft G., Dommelen W., van Espain C., Green P., Hazan V. & Wigforss E. (eds.) (1997) The landscape of future education in speech communication sciences: (1) analysis, Utrecht, Institute of Linguistics, University of Utrecht: OTS Publications.
Bloothooft G., van Dommelen W., Espain C., Hazan V., Huckvale M. & Wigforss E. (eds.) (1998) The landscape of future education in speech communication sciences: (2) proposals, Utrecht, Institute of Linguistics, University of Utrecht: OTS Publications.
Bolt P. & Yazdani M. (1998) "The evolution of a grammar-checking program: LINGER to ISCA", CALL 11, 1: 55-112.
Borchardt F. (1995) "Language and computing at Duke University: or, Virtue Triumphant, for the time being", CALICO Journal 12, 4: 57-83.
Bowerman C. (1993) Intelligent computer-aided language learning. LICE: a system to support undergraduates writing in German, Manchester: UMIST, Unpublished doctoral dissertation.
Brehony T. & Ryan K. (1994) "Francophone stylistic grammar checking (FSGC): using link grammars", CALL 7, 3: 257-269.
Brocklebank P. (1998) An experiment in developing a prototype intelligent teaching system from a parser written in Prolog, Manchester, UMIST, Unpublished MPhil dissertation.
Brown P.F., Della Pietra S.A., Della Pietra V.J. & Mercer R.L. (1993) "The mathematics of statistical Machine Translation: parameter estimation ", Computational Linguistics 19, 2: 263-311.
Buchmann B. (1987) "Early history of Machine Translation". In King M. (ed.) Machine Translation today: the state of the art, Edinburgh: University Press.
Bull S. (1994) "Learning languages: implications for student modelling in ICALL", ReCALL 6, 1: 34-39.
Bureau Lingua/DELTA (1993) Foreign language learning and the use of new technologies, Brussels: European Commission.
Cameron K. (ed.) (1989) Computer Assisted Language Learning, Oxford: Intellect.
Carson-Berndsen J. (1998) "Computational autosegmental phonology in pronunciation teaching". In Jager S., Nerbonne J. & van Essen A. (eds.) Language teaching and language technology, Lisse: Swets & Zeitlinger.
Chanier D., Pengelly M., Twidale M. & Self J. (1992) "Conceptual modelling in error analysis in computer-assisted language learning". In Swartz M. & Yazdani M. (eds.) Intelligent tutoring systems for foreign language learning: the bridge to international communication, Berlin: Springer-Verlag.
Chen L. & Barry L. (1989) "XTRA-TE: Using natural language processing software to develop an ITS for language learning". In Fourth International Conference on Artificial Intelligence and Education: 54-70.
Chomsky N. (1986) Knowledge of language: its nature, origin, and use, New York: Praeger.
Chun D. (1998) "Signal analysis software for teaching discourse intonation", Language Learning and Technology 2, 1: 61-77. Available at: http://llt.msu.edu/vol2num1/article4/index.html
CLEF (Computer-assisted Learning Exercises for French) (1985) Developed by the CLEF Group, Canada, including authors at the University of Guelph, the University of Calgary and the University of Western Ontario. Published by the University of Guelph (Canada) and Camsoft (UK): http://www.camsoftpartners.co.uk/clef.htm
Cole R. (1996) Survey of the state of the art in Human Language Technology: http://www.cslu.ogi.edu/HLTsurvey/. Also published by Cambridge University Press, 1998: ISBN 0-521-59277-1.
Curzon L. B. (1985) Teaching in further education: an outline of principles and practice. London: Holt, Rinehart & Winston, (3rd edition).
Davies G. (1988) "CALL software development". In Jung Udo O.H.. (ed.) Computers in applied linguistics and language learning: a CALL handbook, Frankfurt: Peter Lang.
Davies G. (1996) Total-text reconstruction programs: a brief history, Maidenhead: Camsoft.
Davies S. & Poesio M. (1998) "The provision of corrective feedback in a spoken dialogue system". Unpublished paper presented at the conference on NLP in CALL, May 1998, Manchester: UMIST.
de Bot K., Coste D., Ginsberg R. & Kramsch C. (eds.) (1991) Foreign language research in cross-cultural perspectives, Amsterdam: John Benjamins Publishing Company.
Diaz de Ilarranza A., Maritxalar M. & Oronoz M. (1998) "Reusability of language technology in support of corpus studies in an ICALL environment". In Jager S., Nerbonne J. & van Essen A. (eds.) Language teaching and language technology, Lisse: Swets & Zeitlinger.
Diaz de Ilarranza A., Maritxalar A., Maritxalar M. & Oronoz M. (1999) "IDAZKIDE: An intelligent computer-assisted language learning environment for Second Language Acquisition". In Schulze M., Hamel M-J. & Thompson J. (eds.) Language processing in CALL, ReCALL Special Issue: 12-19.
Dillon G.L. (2003) Resources for studying spoken English. Available at: http://faculty.washington.edu/dillon/PhonResources/PhonResources.html
Dina L. & Malnati G. (1993) "Weak constraints and preference rules". In Bennett P. & Paggio P. (eds.) Preference in EUROTRA, Luxembourg: European Commission.
Dirksen A. & Coleman J. (1995) Introducing IPOX (speech synthesizer). Available at: http://www.phon.ox.ac.uk/~jcoleman/IPOX/ipox.html
Dodigovic M. (2005) Artificial intelligence in second language learning: raising error awareness, Clevedon: Multilingual Matters.
Dokter D. & Nerbonne J. (1998) "A session with Glosser-RuG". In Jager S., Nerbonne J. & van Essen A. (eds.) Language teaching and language technology, Lisse: Swets & Zeitlinger.
Dokter D., Nerbonne J., Schurcks-Grozeva L. & Smit P. (1998) "Glosser-RuG: a user study". In Jager S., Nerbonne J. & van Essen A. (eds.) Language teaching and language technology, Lisse: Swets & Zeitlinger.
Ehsani F. & Knodt E. (1998) "Speech technology in computer-aided language learning: strengths and limitations of a new CALL paradigm", Language Learning and Technology 2, 1: 45-60. Available at: http://llt.msu.edu/vol2num1/article3/index.html
Ellis R. (1994) The study of Second Language Acquisition, Oxford: OUP.
European Commission (1996) Language and technology: from the Tower of Babel to the Global Village, Luxembourg: European Commission. ISBN 92-827-6974-7.
Fechner J. (ed.) (1994) Neue Wege im computergestützten Fremdsprachenunterricht, Berlin: Langenscheidt.
Feuerman K., Marshall C., Newman D. & Rypa M. (1987) "The CALLE project", CALICO Journal 4: 25-34
Foucou P-Y. & Kübler N. (1999) "A Web-based language learning environment: general architecture". In Schulze M., Hamel M-J. & Thompson J. (eds.), Language processing in CALL, ReCALL Special Issue: 31-39.
Fum D., Pani B. & Tasso C. (1992) "Native vs. formal grammars: a case for integration in the design of a foreign language tutor". In Swartz M. & Yazdani M. (eds.) Intelligent tutoring systems for foreign language learning: the bridge to international communication, Berlin: Springer-Verlag
Goodfellow R. & Metcalfe P. (1997) "The challenge: back to basics or brave new world?" In Goodfellow R. & Metcalfe P. (eds.) CALL - the challenge of grammar, ReCALL Special Issue 9, 2: 4-7. Available at: http://www.eurocall-languages.org/recall/pdf/rvol9no2.pdf
Hagen L.K. (1995) "Unification-based parsing applications for intelligent foreign language tutoring systems, CALICO Journal 12, 2-3: 5-31.
Hamilton S. (1998) "A CALL user study". In Jager S., Nerbonne J. & van Essen A.(eds.) Language teaching and language technology, Lisse: Swets & Zeitlinger.
Handke J. (1992) "WIZDOM: a multiple-purpose language tutoring system based on AI techniques". In Swartz M. & Yazdani M. (eds.) Intelligent tutoring systems for foreign language learning: the bridge to international communication, Berlin: Springer-Verlag.
Handley Z. & Hamel M-J. (2005) "Establishing a methodology for benchmarking speech synthesis for CALL", Language Learning and Technology 9, 3: 99-119. Available at: http://llt.msu.edu/vol9num3/handley/default.html
Hart R. (1995) "The Illinois PLATO foreign languages project". In Sanders R. (ed.) (1995) Thirty years of Computer Assisted Language Instruction, Festschrift for John R. Russell, CALICO Journal Special Issue 12, 4: 15-37.
Heift T. (2001) "Error-specific and individualised feedback in a Web-based language tutoring system: Do they read it?" ReCALL 13, 1: 99-109.
Heift T. & Schulze M. (eds.) (2003) Error diagnosis and error correction in CALL, CALICO Journal Special Issue 20, 3.
Heift T. & Schulze M. (2007) Errors and intelligence in CALL: parsers and pedagogues, London and New York: Routledge.
Helbig G. (1975) "Bemerkungen zum Problem von Grammatik und Fremdsprachenunterricht", Deutsch als Fremdsprache 6, 12: 325-332.
Higgins J. & Johns T. (1984) Computers in language learning, London: Collins.
Holland M., Maisano R., Alderks C. & Martin J. (1993) "Parsers in tutors: what are they good for?" CALICO Journal 11, 1: 28-46.
Holland M. & Fisher F.P. (eds.) (2007) The path of speech technologies in Computer Assisted Language Learning: from research toward practice, London and New York: Routledge.
Hutchins W.J. (1986) Machine Translation: past, present, future, Chichester: Ellis Horwood.
Hutchins W.J. (1997) "Fifty years of the computer and translation", Machine Translation Review 6, October 1997: 22-24.
Hutchins W. J. (1999) "The development and use of machine translation systems and computer-based translation tools". Paper given at the International Symposium on Machine Translation and Computer Language Information Processing, 26-28 June 1999, Beijing, China: http://www.foreignword.com/es/Technology/art/Hutchins/hutchins99.htm
Hutchins W.J. & Somers H.L. (1992) An introduction to Machine Translation, London: Academic Press.
Jager S. (2001) "From gap-filling to filling the gap: a re-assessment of Natural Language Processing in CALL". In Chambers A. & Davies G. (eds.) Information and Communications Technology: a European perspective, Lisse: Swets & Zeitlinger.
Jager S., Nerbonne J. & van Essen A. (eds.) (1998) Language teaching and language technology, Lisse: Swets & Zeitlinger.
Jones R. (1995) "TICCIT and CLIPS: The early years". In Sanders R. (ed.) (1995) Thirty years of Computer Assisted Language Instruction, Festschrift for John R. Russell, CALICO Journal Special Issue 12, 4: 84-96.
Jung Udo O.H. & Vanderplank R. (eds.) (1994) Barriers and bridges: media technology in language learning: proceedings of the 1993 CETall Symposium on the occasion of the 10th AILA World Congress in Amsterdam, Frankfurt: Peter Lang.
Juozulynas V. (1994) "Errors in the composition of second-year German students: an empirical study of parser-based ICALI", CALICO Journal 12, 1: 5-17.
King M. (ed.) (1987) Machine Translation today: the state of the art, Edinburgh: Edinburgh University Press.
Klein W. & Dittmar N. (1979) Developing grammars: the acquisition of German syntax by foreign workers, Heidelberg: Springer.
Klein W. & Perdue C. (1992) Utterance structure (developing grammars again), Amsterdam: John Benjamins Publishing Company.
Klein W. (1986) Second language acquisition, Cambridge: Cambridge University Press.
Kohn K. (1994) "Distributive language learning in a computer-based multilingual communication environment". In Jung Udo O.H. & Vanderplank R. (eds.) Barriers and bridges: media technology in language learning: proceedings of the 1993 CETall Symposium on the occasion of the 10th AILA World Congress in Amsterdam, Frankfurt: Peter Lang.
Krashen S. (1981) Second language acquisition and second language learning, Oxford: Pergamon.
Krashen S. (1982) Principles and practice in second language acquisition, Oxford: Pergamon.
Krüger-Thielmann K. (1992) Wissensbasierte Sprachlernsysteme. Neue Möglichkeiten für den computergestützten Sprachunterricht, Tübingen: Gunter Narr.
Labrie G. & Singh L. (1991) "Parsing, error diagnosis and instruction in a French tutor", CALICO Journal 9: 9-25.
Last R. (1989) Artificial Intelligence techniques in language learning, Chichester: Ellis Horwood.
Last R. (1992) "Computers and language learning: past, present - and future?" In Butler C. (ed.) Computers and written texts, Oxford: Blackwell.
Levin L., Evans D. & Gates D. (1991) "The Alice system: a workbench for learning and using language", CALICO Journal 9: 27-55.
Levy M. (1997) Computer-assisted language learning: context and conceptualisation, Oxford: Oxford University Press.
Lightbown P.M. & Spada N. (1993) How languages are learned, Oxford: Oxford University Press.
Long M. (1991) "Focus on form: a design feature in language teaching methodology". In de Bot K., Coste D., Ginsberg R. & Kramsch C. (eds.)Foreign language research in cross-cultural perspectives, Amsterdam: John Benjamins Publishing Company.
Manning C. & Schütze H. (1999) Foundations of statistical Natural Language Processing, Cambridge MA, MIT Press.
Matthews C. (1992a) "Going AI: foundations of ICALL", CALL 5, 1-2: 13-31.
Matthews C. (1992b) Intelligent CALL (ICALL) bibliography, Hull: University of Hull, CTI Centre for Modern Languages.
Matthews C. (1993) "Grammar frameworks in Intelligent CALL", CALICO Journal 11, 1: 5-27.
Matthews C. (1994) "Intelligent Computer Assisted Language Learning as cognitive science: the choice of syntactic frameworks for language tutoring", Journal of Artificial Intelligence in Education 5, 4: 533-56.
Menzel W. & Schröder I. (1999) "Error diagnosis for language learning systems". In Schulze M., Hamel M-J. & Thompson J. (eds.), Language processing in CALL, ReCALL Special Issue: 20-30.
Michel G. (ed.) (1985) Grundfragen der Kommunikationsbefähigung, Leipzig: Bibliographisches Institut.
Mitkov R. (1998) Language Learner's Workbench. Unpublished paper presented at the conference on NLP in CALL, May 1998, Manchester: UMIST.
Mitkov R. & Nicolov N. (eds.) (1997) Recent advances in Natural Language Processing. Amsterdam: John Benjamins Publishing Company.
Murphy M., Krüger A. & Griesz A., (1998) "RECALL "-towards a knowledge-based approach to CALL. In Jager S., Nerbonne J. & van Essen A.(eds.), Language teaching and language technology, Lisse: Swets & Zeitlinger.
Nagata N. (1996) "Computer vs. workbook instruction in second language acquisition", CALICO Journal 14, 1: 53-75.
Nerbonne J., Jager S. & van Essen A. (1998) Introduction. In Jager S., Nerbonne J. & van Essen A.(eds.), Language teaching and language technology, Lisse: Swets & Zeitlinger.
Nirenburg S. (ed.) (1986) Machine Translation: theoretical and methodological issues, Cambridge: Cambridge University Press.
Pijls F., Daelmans W. & Kempen G. (1987) "Artificial intelligence tools for grammar and spelling instruction, Instructional Science 16: 319-336.
Pollard C. & Sag I.A. (1987) Information-Based Syntax and Semantics, Chicago: University Press.
Pollard C. & Sag I.A. (1994) Head-Driven Phrase Structure Grammar, Chicago: University Press.
Ramsay A. & Schäler R. (1997) "Case and word order in English and German". In Mitkov R. & Nicolov N. (eds.) Recent advances in Natural Language Processing, Amsterdam: John Benjamins Publshing Company: 15-34.
Ramsay A. & Schulze M. (1999) "Die Struktur deutscher Lexeme", German Linguistic and Cultural Studies, Peter Lang, Submitted Manuscript.
Reifler E. (1958) "The Machine Translation project at the University of Washington, Seattle, Washington, USA". In Proceedings of the Eighth International Congress of Linguists, Oslo University Press: 514-518.
Roosmaa T. & Prószéky G. (1998) "GLOSSER - using language technology tools for reading texts in a foreign language". In Jager S., Nerbonne J. & van Essen A. (eds.) Language teaching and language technology, Lisse: Swets & Zeitlinger.
Salaberry R. (1996) "A theoretical foundation for the development of pedagogical tasks in computer mediated communication", CALICO Journal 14, 1: 5-34.
Sanders R. (1991) "Error analysis in purely syntactic parsing of free input: the example of German", CALICO Journal 9, 1: 72-89.
Sanders R. (ed.) (1995) Thirty years of Computer Assisted Language Instruction, Festschrift for John R. Russell, CALICO Journal Special Issue 12, 4.
Schmitz U. (1992) Computerlinguistik, Opladen: Westdeutscher Verlag.
Schulze M. (1997) "Textana - text production in a hypertext environment", CALL 10, 1: 71-82.
Schulze M. (1998) "Teaching grammar - learning grammar. Aspects of Second Language Acquisition in CALL", CALL 11, 2: 215-228.
Schulze M. (1999) "From the
developer to the learner: computing grammar - learning grammar", ReCALL
11, 1: 117-124. Available at
http://www.eurocall-languages.org/recall/pdf/rvol11no1.pdf
Schulze M. (2001) "Human Language Technologies in Computer Assisted Language Learning". In Chambers A. & Davies G. (eds.) Information and Communications Technology: a European perspective, Lisse: Swets & Zeitlinger.
Schulze M., Hamel M-J. & Thompson J. (eds.) (1999) Language processing in CALL, ReCALL Special Issue.
Schumann J.H. & Stenson N. (eds.) (1975) New frontiers in second language learning, Rowley: Newbury House.
Schwind C. (1990) "An intelligent language tutoring system", International Journal of Man-Machine Studies 33: 557-579
Selinker L. (1992) Rediscovering interlanguage, London: Longman.
Skrelin P. & Volskaja N. (1998) "The application of new technologies in the development of education programs". In Jager S., Nerbonne J. & van Essen A. (eds.), Language teaching and language technology, Lisse: Swets & Zeitlinger.
Smith R. (1990) Dictionary of Artificial Intelligence, London: Collins.
Späth P. (1994) "Hypertext und Expertensysteme im Sprachunterricht". In Fechner J. (ed.) Neue Wege im computergestützten Fremdsprachenunterricht, Berlin: Langenscheidt.
Stenzel B. (ed.) (1985) Computergestützter Fremdsprachenunterricht. Ein Handbuch, Berlin: Langenscheidt.
Swartz M. & Yazdani M. (eds.) (1992) Intelligent tutoring systems for foreign language learning: the bridge to international communication, Berlin: Springer-Verlag.
Taylor H. (1987) TUCO II. Published by Gessler Educational Software, New York. Based on earlier programs developed by Taylor H. & Haas W. at Ohio State University in the 1970s: DECU (Deutscher Computerunterricht) and TUCO (Tutorial Computer).
Taylor H. (1998) Computer assisted text production: feedback on grammatical errors made by learners of English as a Foreign Language, Manchester: UMIST, MSc Dissertation.
Tschichold C. (1999) "Intelligent grammar checking for CALL". In Schulze M., Hamel M-J. & Thompson J. (eds.) Language processing in CALL, ReCALL Special Issue: 5-11.
Tschichold C., Bodme F., Cornu E., Grosjean F., Grosjean L., Kübler N. & Tschumi C. (1994) "Detecting and correcting errors in second language texts", CALL 7, 2: 151-160.
Turing A. (1948) Intelligent Machinery. London: National Physical Laboratory: http://www.alanturing.net/turing_archive/archive/l/l32/L32-001.html
University College London (1998)
UCL Tutorials in Speech Communication Science. Available at:
http://www.phon.ucl.ac.uk/home/wbt/ucltutor.htm
Visser H. (1999) "CALLex (Computer-Aided Learning of Lexical functions) - a CALL game to study lexical relationships based on a semantic database". In Schulze M., Hamel M-J. & Thompson J. (eds.), Language processing in CALL, ReCALL Special Issue: 50-56.
Ward R., Foot R. & Rostron A.B. (1999) "Language processing in computer-assisted language learning: language with a purpose". In Schulze M., Hamel M-J. & Thompson J. (eds.) Language processing in CALL, ReCALL Special Issue: 40-49.
Weaver W. (1949) Warren Weaver Memorandum, "Translation". Reproduced in Locke W.N. & Booth A.D. (eds.) (1955) Machine translation of languages: fourteen essays, Cambridge, Mass: Technology Press of the Massachusetts Institute of Technology: 15-23.
Weaver W. (1949) Warren Weaver Memorandum, "Translation". See "50th
anniversary of machine translation", MT News International, Issue
22 (Vol. 8, 1), July 1999: 5-6.
Weischedel R., Voge W. & James M. (1978) "An artificial intelligence approach to language instruction", Artificial Intelligence 10: 225-240.
Wilks Y. & Farwell D. (1992) "Building an intelligent second language tutoring system from whatever bits you happen to have lying around". In Swartz M. & Yazdani M. (eds.) Intelligent tutoring systems for foreign language learning: the bridge to international communication, Berlin: Springer-Verlag,
Whitelock P.J. & Kilby K. (1995) Linguistic and computational techniques in Machine Translation system design, London: University College Press.
Witt S. & Young S. (1998) "Computer-assisted pronunciation teaching based on automatic speech recognition". In Jager S., Nerbonne J. & van Essen A. (eds.), Language teaching and language technology, Lisse: Swets & Zeitlinger.
Wolff D. (1993) "New technologies for foreign language teaching". In Foreign language learning and the use of new technologies, Bureau Lingua/DELTA, Brussels, European Commission.
Young S. & Bloothooft G. (eds.) (1997) Corpus-based methods in language and speech processing, Dordrecht: Kluwer AcademicPublishers.
Zähner C. (1991) "Word grammars in ICALL". In Savolainen H. & Telenius J. (eds.) EuroCALL 91 proceedings, Helsinki: Helsinki School of Economics.
Zech J. (1985) "Methodische Probleme einer tätigkeitsorientierten Ausbildung des sprachlich-kommunikativen Könnens". In Michel G. (ed.) Grundfragen der Kommunikationsbefähigung, Leipzig: Bibliographisches Institut.
CALICO (Computer Assisted Language Instruction Consortium): CALICO is a professional association devoted to promoting the use of technology enhanced language learning. Founded in the USA in 1982: http://www.calico.org/. CALICO's sister association in Europe is EUROCALL.
Center for Spoken Language Understanding (CSLU): Based at the Oregon Health and Science University, focusing on spoken language technologies: http://ogi.edu/bme/cslu/
EUROCALL: EUROCALL is a professional association devoted to promoting the use of technology enhanced language learning, based at the University of Ulster, Northern Ireland. EUROCALL's sister association in the USA is CALICO.
ICALL: The name of the Special Interest Group in Intelligent Computer Assisted Language Learning within the CALICO professional association: http://purl.org/calico/icall. ICALL is an interdisciplinary research field integrating insights from computational linguistics and artificial intelligence into computer-aided language learning. Such integration is needed for CALL systems to be able to analyze language automatically, to make them aware of language as such. This makes it possible to provide individualized feedback to learners working on exercises, to (semi-)automatically prepare or enhance texts for learners, and to automatically create and use detailed learner models. See NLP SIG, the Special Interest Group within EUROCALL, with which ICALL closely collaborates.
InSTIL: The name of a now defunct Special Interest Group dedicated to Integrating Speech Technology in Language Learning, which was set up within the EUROCALL and CALICO professional associations. It's website at http://dbs.tay.ac.uk/instil/index.htm died some time ago, but you may find an archived version if you enter its URL into the Internet Archive (the Wayback Machine) at http://www.archive.org/. A good deal of the work undertaken by InSTIL has now been taken over by ICALL and NLP SIG.
Morphy: A Windows tagger
and morphological analyser for German by Wolfgang Lezius:
http://www.wolfganglezius.de/doku.php?id=public:cl:morphy
NLP SIG: The name of the Special Interest Group for Natural Language Processing within the EUROCALL professional association. It aims to further research in a number of areas that are mentioned in this module, such as: Artificial Intelligence, Computational Linguistics, Corpus-Driven and Corpus Linguistics, Formal Linguistics, Machine Aided Translation, Machine Translation, Natural Language Interfaces, Natural Language Processing, Theoretical Linguistics, all of which are areas of research that have produced results which have proven, are proving and will prove very useful in the field of Computer Assisted Language Learning: http://siglp.eurocall-languages.org/. The NLP SIG also maintains a Ning: http://nlpsig.ning.com/. See ICALL, the Special Interest Group within CALICO, with which NLP SIG closely collaborates.
Nuance: Markets speech recognition software: http://www.nuance.com/
PC-Patr Syntactic Parser: downloadable from http://www.sil.org/pcpatr/
Virtual Linguistics Campus:
It includes a virtual lecture hall where the student can attend linguistics
courses, a linguistics lab,chat rooms, message boards, etc. Some sections are
only accessible if you have registered, but there are a lot of materials that
are open to all: http://linguistics.online.uni-marburg.de/
Visual Interactive Syntax Learning (VISL): A variety tools for different languages can be found here: sentence analysis, corpora, machine translation, as well as games and quizzes: http://visl.sdu.dk/
If you wish to send us feedback on any aspect of the ICT4LT website, use our online Feedback Form or visit the ICT4LT blog.
![]()
The Feedback Form and a link to the ICT4LT blog can be found at the bottom of every page at the ICT4LT site.
Document last updated 29 April 2012. This page is maintained by Graham Davies.
Please cite this
Web page as:
Gupta P. & Schulze M. (2012) Human Language Technologies (HLT). Module 3.5
in Davies G. (ed.) Information and Communications Technology for Language
Teachers (ICT4LT), Slough, Thames Valley University [Online]. Available
at: http://www.ict4lt.org/en/en_mod3-5.htm
[Accessed DD Month YYYY].
© Sarah Davies in association with MDM creative. This work is licensed under a
Creative
Commons Attribution-NonCommercial-NoDerivs 3.0 Unported License.
